Data concepts
Last update: 20230619
Table of contents
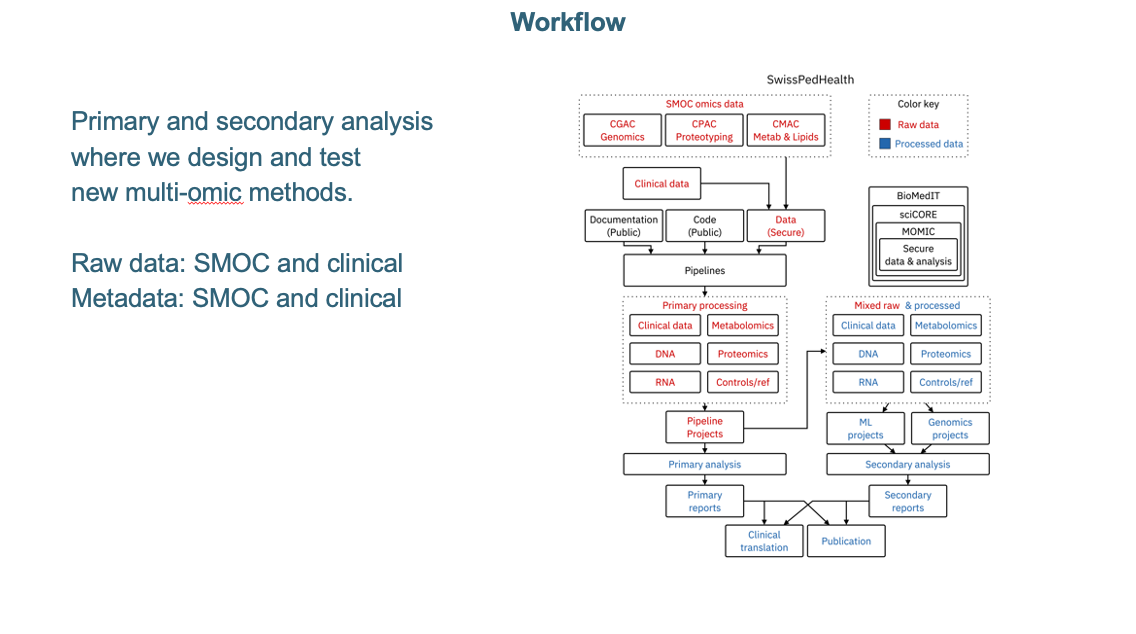
How data is collected and stored
- The Swiss Personalised Health Network (SPHN): collects and hosts omic data that we will ultimately use
- Branch of SPHN: Data Coordination Center (DCC)
- DCC is also a part of Swiss Institute of Bioinformatics (SIB)
- The data is to be stored and processed on BioMedIT network
- Our tenant on BioMedIT is called MOMIC and this is on the sciCORE infrastructure.
- The database structure requires Resource Description Framework (RDF) Schema
Database concepts
The DCC is responsible for making research data suitable for database management. To do this they design the concepts. Training material available here, but is a DCC responsibility.
Several concepts for the types of data that we use alredy exist. e.g. genetic data concepts.
We also assist in generating new omics-related concepts for future expansion. This page will be updated to summarise the progress as these new concepts are defined.

Availability
The following information is copied from https://sphn.ch/2023/03/20/sphn-dataset-rdf-schema-2023-release/
- The SPHN Dataset is openly available here: https://sphn.ch/document/sphn-dataset/
- The SPHN RDF Schema is browsable here: https://www.biomedit.ch/rdf/sphn-ontology/sphn/2023/2
- The external terminologies in RDF are accessible on BioMedIT Portal: https://portal.dcc.sib.swiss/
- The Quality Assurance Framework is available here: https://git.dcc.sib.swiss/sphn-semantic-framework/sphn-ontology/-/tree/master/quality_assurance
- Project templates are available here: https://git.dcc.sib.swiss/sphn-semantic-framework/sphn-ontology/-/tree/master/templates
- A comprehensive documentation is openly accessible here: https://sphn-semantic-framework.readthedocs.io/en/latest/
Specific genetic examples
- https://www.biomedit.ch/rdf/sphn-ontology/sphn/2023/2#GeneticVariation
- https://www.biomedit.ch/rdf/sphn-ontology/sphn/2023/2#SingleNucleotideVariation
- https://www.biomedit.ch/rdf/sphn-ontology/sphn/2023/2#VariantDescriptor
- https://www.biomedit.ch/rdf/sphn-ontology/sphn/2023/2#VariantNotation
Potential concepts


Examples
Genomics England (GE)
GE represents one of the best national platforms so far and they have complete analysis of ~200’000 genomes for clinical use.
GE model documentation shows the concepts in use: http://gelreportmodels.genomicsengland.co.uk/models.html#. Concept development could start with the GE 1.3.0-SNAPSHOT. For example, VariantMetadata is a good starting place since it includes “individual” (i.e. subject), “sample type”, “experiment”, etc., which are required in most genomic data scenarios. We could work through a prioritised list of concepts over several months-years for any new concept that matches user requirements. They have derived some logical structures derived from Ontobee, OpenCB, and probably other common sources.
Example: metadata
Here are some examples which most users will require, from VariantMetadata:
|--VariantMetadata:
|-- Cohort
|-- Experiment
|--- center, date, molecule, technique, library, libraryLayout, platform, description
|-- Individual
|-- id, family, father, mother, sex, phenotype, samples
|-- Program
|-- ...
|-- Sample
|-- ...
|-- SampleSetType
|-- CASE_CONTROL, CASE_SET, CONTROL_SET, PAIRED, TIME_SERIES, FAMILY, TRIO, MISCELLANEOUS, UNKNOWN
|--Species
|-- ...
Example: variant Some of the most important concepts for our genomics needs are listed on the variant procol page, which come from org.opencb.biodata.models.variant.avro. These are beyond our current needs but this list of 55 entries likely cover most of the conceivable needs:
AdditionalAttribute, AlleleOrigin Enum, AllelesCode Enum, AlternateCoordinate, ClinVar, ClinicalSignificance Enum, Confidence Enum, ConsequenceType, ConsistencyStatus Enum, Cosmic, Cytoband, Drug, DrugResponseClassification Enum, EthnicCategory Enum, EvidenceEntry, EvidenceImpact Enum, EvidenceSource, EvidenceSubmission, ExonOverlap, Expression, ExpressionCall Enum, FeatureTypes Enum, FileEntry, GeneDrugInteraction, GeneTraitAssociation, GenomicFeature, Genotype, Gwas, HeritableTrait, ModeOfInheritance Enum, Penetrance Enum, PopulationFrequency, Property, ProteinFeature, ProteinVariantAnnotation, Repeat, Score, SequenceOntologyTerm, SomaticInformation, StructuralVariantType Enum, StructuralVariation, StudyEntry, TraitAssociation Enum, TumorigenesisClassification Enum, VariantAnnotation, VariantAvro, VariantClassification, VariantFunctionalEffect Enum, VariantHardyWeinbergStats, VariantStats, VariantTraitAssociation, VariantType Enum, Xref,
Let’s pick one example from that list which would come under the heading “variant interpretation” - ClinicalSignificance:
Example: variant interpretation - ClinicalSignificance
We use this exact example for our clinical genetics work: ClinicalSignificance.
Mendelian variants classification with ACMG terminology as defined in Richards, S. et al. (2015). Standards and guidelines for the interpretation of sequence variants: a joint consensus recommendation of the American College of Medical Genetics and Genomics and the Association for Molecular Pathology. Genetics in Medicine, 17(5), 405?423. https://doi.org/10.1038/gim.2015.30.
Classification for variants associated with disease, etc., based on the ACMG recommendations and ClinVar classification (https://www.ncbi.nlm.nih.gov/clinvar/docs/clinsig/).
benign_variant: Benign variants interpreted for Mendelian disorderslikely_benign_variant: Likely benign variants interpreted for Mendelian disorders with a certainty of at least 90%pathogenic_variant: Pathogenic variants interpreted for Mendelian disorderslikely_pathogenic_variant: Likely pathogenic variants interpreted for Mendelian disorders with a certainty of at least 90%uncertain_significance: Uncertain significance variants interpreted for Mendelian disorders. Variants with conflicting evidences should be classified as uncertain_significance- Enum symbols:
benign,likely_benign,VUS,likely_pathogenic,pathogenic,uncertain_significance
However, we do not restrict our use of ACMG standard for variant interpretation using only ClinicalSignificance, since there are a large number of other variant interpretation datasets which can be used to make the final determination. One method we use is the ACMG scoring sytem to score all variants based on the ACMG evidence categorisation method. Therefore, ACMG_score could be derived from ClinicalSignificance, but also from other sources. Perhaps EvidenceEntry is a major entry which includes most of these subtypes for interpretation evidence.
OpenCB
- Used for some Genomics England concepts
- OpenCB which provides scalable a storage engine framework with data and metadata catalogue.
- https://github.com/opencb/opencga
- http://docs.opencb.org
Ontobee
- Used for some Genomics England concepts
- Ontology data server with RDF source code.
- Example GE concept for “Variants / AlleleOrigin / germline_variant” comes from :
- https://ontobee.org/ontology/SO?iri=http://purl.obolibrary.org/obo/SO_0001762
- germline_variant RDF source code
|-- sequence_attribute
|-- variant_quality
|-- variant_origin
|-- maternal_variant
|-- paternal_variant
|-- somatic_variant
|-- pedigree_specific_variant
|-- population_specific_variant
|-- de_novo_variant
|-- germline_variant
|-- RDF sourcode